Evaluation of Speech for the Google Assistant
December 21, 2017
Posted by Enrique Alfonseca, Staff Research Scientist, Google Assistant
Quick links
Voice interactions with technology are becoming a key part of our lives — from asking your phone for traffic conditions to work to using a smart device at home to turn on the lights or play music. The Google Assistant is designed to provide help and information across a variety of platforms, and is built to bring together a number of products — including Google Maps, Search, Google Photos, third party services, and more. For some of these products, we have released specific evaluation guidelines, like Search Quality Rating Guidelines. However, the Google Assistant needs its own guidelines in place, as many of its interactions utilize what is called “eyes-free technology,” when there is no screen as part of the experience.
In the past we have received requests to see our evaluation guidelines from academics who are researching improvements in voice interactions, question answering and voice-guided exploration. To facilitate their evaluations, we are publishing some of the first Google Assistant guidelines. It is our hope that making these guidelines public will help the research community build and evaluate their own systems.
Creating the Guidelines
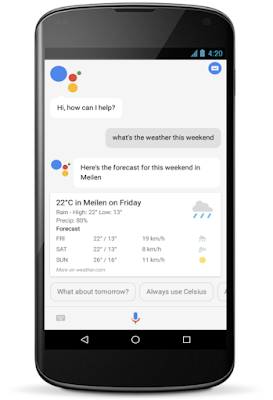
For many queries, responses are presented on the display (like a phone) with a graph, a table, or an interactive element, like you’d see for [weather this weekend].

How do we ensure that we consistently meet user expectations on quality, across all answer types and languages? One of the tools we use to measure that are human evaluations. In these, we ask raters to make sure that answers are satisfactory across several dimensions:
- Information Satisfaction: the content of the answer should meet the information needs of the user.
- Length: when a displayed answer is too long, users can quickly scan it visually and locate the relevant information. For voice answers, that is not possible. It is much more important to ensure that we provide a helpful amount of information, hopefully not too much or too little. Some of our previous work is currently in use for identifying the most relevant fragments of answers.
- Formulation: it is much easier to understand a badly formulated written answer than an ungrammatical spoken answer, so more care has to be placed in ensuring grammatical correctness.
- Elocution: spoken answers must have proper pronunciation and prosody. Improvements in text-to-speech generation, such as WaveNet and Tacotron 2, are quickly reducing the gap with human performance.
-
Labels:
- Product
- Speech Processing
Quick links
Other posts of interest
-

July 2, 2025
Making group conversations more accessible with sound localization- Human-Computer Interaction and Visualization ·
- Sound & Accoustics ·
- Speech Processing
-
May 6, 2025
Making complex text understandable: Minimally-lossy text simplification with Gemini- Generative AI ·
- Health & Bioscience ·
- Product
-
March 21, 2025
Deciphering language processing in the human brain through LLM representations- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Speech Processing