Revisiting the Unreasonable Effectiveness of Data
July 11, 2017
Posted by Abhinav Gupta, Faculty Advisor, Machine Perception
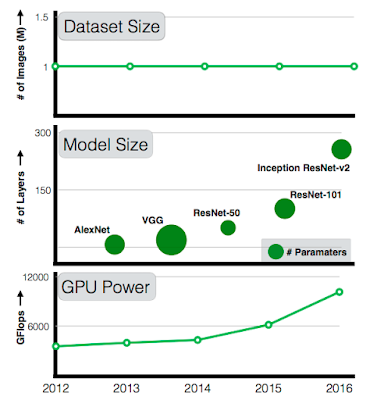
There has been remarkable success in the field of computer vision over the past decade, much of which can be directly attributed to the application of deep learning models to this machine perception task. Furthermore, since 2012 there have been significant advances in representation capabilities of these systems due to (a) deeper models with high complexity, (b) increased computational power and (c) availability of large-scale labeled data, much of which is publicly available. And while every year we get further increases in computational power and the model complexity (from 7-layer AlexNet to 101-layer ResNet), available datasets have not scaled accordingly. A 101-layer ResNet with significantly more capacity than AlexNet is still trained with the same 1M images from ImageNet circa 2011. As researchers, we have always wondered: if we scale up the amount of training data 10x, will the accuracy double? How about 100x or maybe even 300x? Will the accuracy plateau or will we continue to see increasing gains with more and more data?
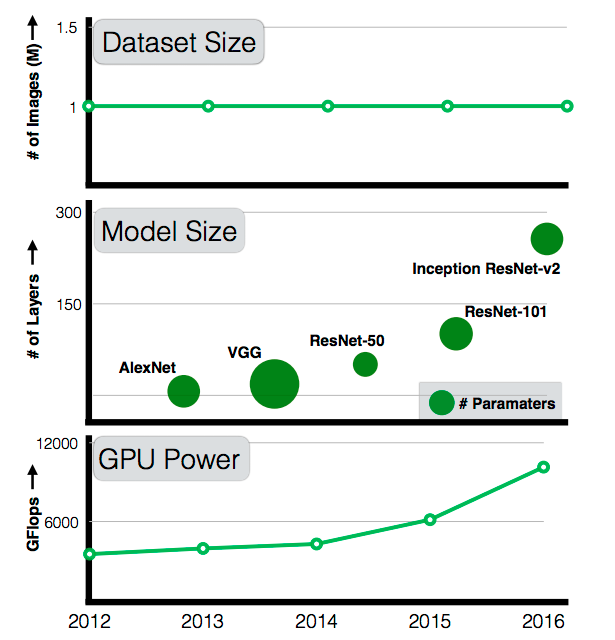 |
| While GPU computation power and model sizes have continued to increase over the last five years, the size of the largest training dataset has surprisingly remained constant. |
Of course, the elephant in the room is where can we obtain a dataset that is 300x larger than ImageNet? At Google, we have been continuously working on building such datasets automatically to improve computer vision algorithms. Specifically, we have built an internal dataset of 300M images that are labeled with 18291 categories, which we call JFT-300M. The images are labeled using an algorithm that uses complex mixture of raw web signals, connections between web-pages and user feedback. This results in over one billion labels for the 300M images (a single image can have multiple labels). Of the billion image labels, approximately 375M are selected via an algorithm that aims to maximize label precision of selected images. However, there is still considerable noise in the labels: approximately 20% of the labels for selected images are noisy. Since there is no exhaustive annotation, we have no way to estimate the recall of the labels.
Our experimental results validate some of the hypotheses but also generate some unexpected surprises:
- Better Representation Learning Helps. Our first observation is that large-scale data helps in representation learning which in-turn improves the performance on each vision task we study. Our findings suggest that a collective effort to build a large-scale dataset for visual pretraining is important. It also suggests a bright future for unsupervised and semi-supervised representation learning approaches. It seems the scale of data continues to overpower noise in the label space.
- Performance increases logarithmically based on volume of training data. We find there is a logarithmic relationship between performance on vision tasks and the amount of training data used for representation learning.
- Capacity is Crucial. We also observe that to fully exploit 300M images, one needs higher capacity (deeper) models. For example, in case of ResNet-50 the gain on COCO object detection benchmark is much smaller (1.87%) compared to (3%) when using ResNet-152.
- New state of the art results. Our paper presents new state-of-the-art results on several benchmarks using the models learned from JFT-300M. For example, a single model (without any bells and whistles) can now achieve 37.4 AP as compared to 34.3 AP on the COCO detection benchmark.
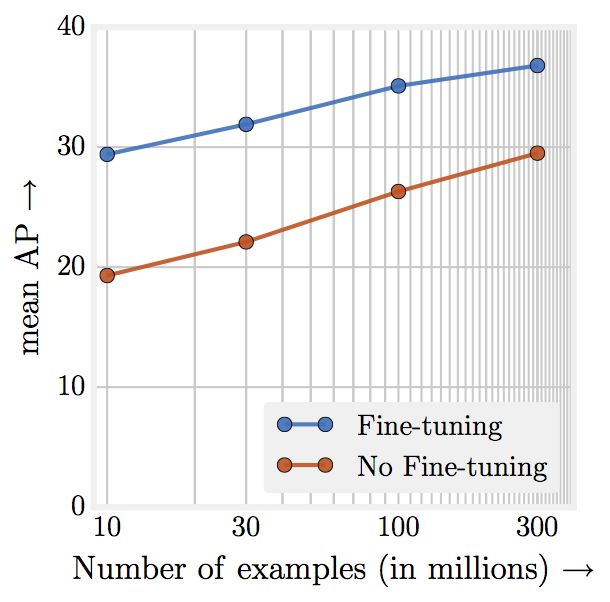 |
| Object detection performance when pre-trained on different subsets of JFT-300M from scratch. x-axis is the dataset size in log-scale, y-axis is the detection performance in mAP@[.5,.95] on COCO-minival subset. |
This work does not focus on task-specific data, such as exploring if more bounding boxes affects model performance. We believe that obtaining large scale task-specific data should be the focus of future study. Google has already released several large scale datasets such as Open Images and YouTube-8M to further these goals. Furthermore, building a dataset of 300M images should not be a final goal - as a community, we should explore if models continue to improve in a meaningful way in the regime of even larger (1 billion+ image) datasets.
Core Contributors
Chen Sun, Abhinav Shrivastava, Saurabh Singh, and Abhinav Gupta
Acknowledgments
This work would not have been possible without the significant efforts of the Image Understanding and Expander teams at Google who built the massive JFT dataset. We would specifically like to thank Tom Duerig, Neil Alldrin, Howard Zhou, Lu Chen, David Cai, Gal Chechik, Zheyun Feng, Xiangxin Zhu and Rahul Sukthankar for their help. Also big thanks to the VALE team for APIs and specifically, Jonathan Huang, George Papandreou, Liang-Chieh Chen and Kevin Murphy for helpful discussions.
Other posts of interest
-

April 23, 2024
Safely repairing broken builds with ML- Machine Intelligence ·
- Software Systems & Engineering
-

April 17, 2024
Robust speech recognition in AR through infinite virtual rooms with acoustic modeling- Human-Computer Interaction and Visualization ·
- Machine Perception ·
- Speech Processing
-

April 12, 2024
Contrastive neural audio separation- Machine Intelligence ·
- Sound & Accoustics