Using Machine Learning to Predict Parking Difficulty
February 3, 2017
Posted by James Cook, Yechen Li, Software Engineers and Ravi Kumar, Research Scientist
"When Solomon said there was a time and a place for everything he had not encountered the problem of parking his automobile." -Bob Edwards, Broadcast Journalist
Much of driving is spent either stuck in traffic or looking for parking. With products like Google Maps and Waze, it is our long-standing goal to help people navigate the roads easily and efficiently. But until now, there wasn’t a tool to address the all-too-common parking woes.
Last week, we launched a new feature for Google Maps for Android across 25 US cities that offers predictions about parking difficulty close to your destination so you can plan accordingly. Providing this feature required addressing some significant challenges:
- Parking availability is highly variable, based on factors like the time, day of week, weather, special events, holidays, and so on. Compounding the problem, there is almost no real time information about free parking spots.
- Even in areas with internet-connected parking meters providing information on availability, this data doesn’t account for those who park illegally, park with a permit, or depart early from still-paid meters.
- Roads form a mostly-planar graph, but parking structures may be more complex, with traffic flows across many levels, possibly with different layouts.
- Both the supply and the demand for parking are in constant flux, so even the best system is at risk of being outdated as soon as it’s built.
Three technical pieces were required to build the algorithms behind the parking difficulty feature: good ground truth data from crowdsourcing, an appropriate ML model and a robust set of features to train the model on.
Ground Truth Data
Gathering high-quality ground truth data is often a key challenge in building any ML solution. We began by asking individuals at a diverse set of locations and times if they found the parking difficult. But we learned that answers to subjective questions like this produces inconsistent results - for a given location and time, one person may answer that it was “easy” to find parking while another found it “difficult.” Switching to objective questions like “How long did it it take to find parking?” led to an increase in answer confidence, enabling us to crowdsource a high-quality set of ground truth data with over 100K responses.
Model Features
With this data available, we began to determine features we could train a model on. Fortunately, we were able to turn to the wisdom of the crowd, and utilize anonymous aggregated information from users who opt to share their location data, which already is a vital source of information for estimates of live traffic or popular times and visit durations.
We quickly discovered that even with this data, some unique challenges remain. For example, our system shouldn’t be fooled into thinking parking is plentiful if someone is parking in a gated or private lot. Users arriving by taxi might look like a sign of abundant parking at the front door, and similarly, public-transit users might seem to park at bus stops. These false positives, and many others, all have the potential to mislead an ML system.
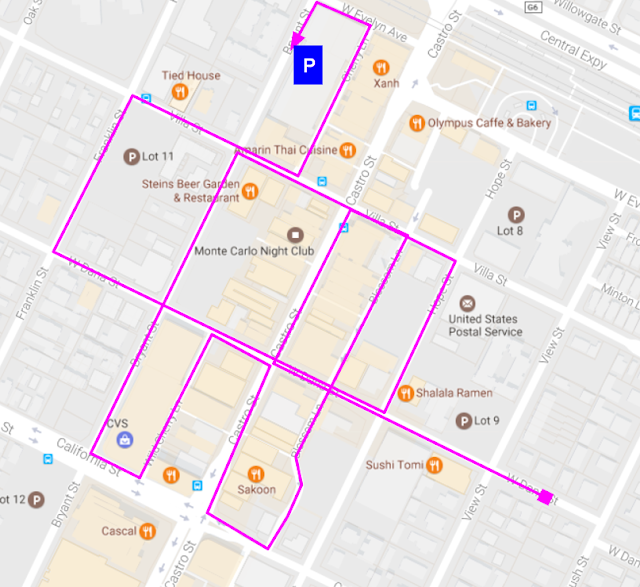
So we needed more robust aggregate features. Perhaps not surprisingly, the inspiration for one of these features came from our own backyard in downtown Mountain View. If Google navigation observes many users circling downtown Mountain View during lunchtime along trajectories like this one, it strongly suggests that parking might be difficult:

From there, we continued to develop more features that took into account, for any particular destination, dispersion of parking locations, time-of-day and date dependence of parking (e.g. what if users park close to a destination in the early morning, but further away at busier hours?), historical parking data and more. In the end, we decided on roughly twenty different features along these lines for our model. Then it was time to tune the model performance.
Model Selection & Training
We decided to use a standard logistic regression ML model for this feature, for a few different reasons. First, the behavior of logistic regression is well understood, and it tends to be resilient to noise in the training data; this is a useful property when the data comes from crowdsourcing a complicated response variable like difficulty of parking. Second, it’s natural to interpret the output of these models as the probability that parking will be difficult, which we can then map into descriptive terms like “Limited parking” or “Easy.” Third, it’s easy to understand the influence of each specific feature, which makes it easier to verify that the model is behaving reasonably. For example, when we started the training process, many of us thought that the “fingerprint” feature described above would be the “silver bullet” that would crack the problem for us. We were surprised to note that this wasn’t the case at all — in fact, it was features based on the dispersion of parking locations that turned out to be one of the most powerful predictors of parking difficulty.
Results
With our model in hand, we were able to generate an estimate for difficulty of parking at any place and time. The figure below gives a few examples of the output of our system, which is then used to provide parking difficulty estimates for a given destination. Parking on Monday mornings, for instance, is difficult throughout the city, especially in the busiest financial and retail areas. On Saturday night, things are busy again, but now predominantly in the areas with restaurants and attractions.
 |
| Output of our parking difficulty model in the Financial District and Union Square areas of San Francisco. Red denotes a higher confidence that parking is difficult. Top row: a typical Monday at ~8am (left) and ~9pm (right). Bottom row: the same times but on a typical Saturday. |
-
Labels:
- Machine Intelligence
- Product
Other posts of interest
-

April 23, 2024
Safely repairing broken builds with ML- Machine Intelligence ·
- Software Systems & Engineering
-

April 19, 2024
Improving Gboard language models via private federated analytics- Algorithms & Theory ·
- Distributed Systems & Parallel Computing ·
- Product ·
- Security, Privacy and Abuse Prevention
-

April 12, 2024
Contrastive neural audio separation- Machine Intelligence ·
- Sound & Accoustics