Chat Smarter with Allo
May 18, 2016
Posted by Pranav Khaitan, Google Research
Quick links
At Google, we are continuously building products powered by Machine Learning to delight our users and simplify their lives. Today, we are excited to talk about the technology behind Allo, a new smart messaging app that uses the power of neural networks and Google Search to make your text conversations easier and more productive.
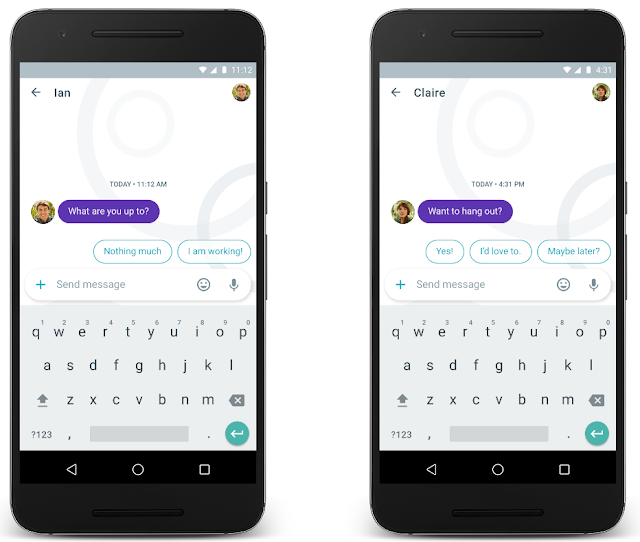
Just like Smart Reply for Inbox, Allo understands the conversation history to generate a set of suggestions that the user will likely want to respond with. In addition to understanding the context of your conversation, Allo learns your individual style, so the responses are personalized for you.

About a year ago, we started exploring how we can make communication easier and more fun. The idea of Smart Reply for Allo came up in a brainstorming session with my teammates Sushant Prakash and Ori Gershony who then helped me lead our team to build this technology. We began by experimenting with neural network based model architectures which had proven to be successful for sequence prediction, including the encoder-decoder model used in Smart Reply for Inbox.
One challenge we faced was that response generation in online conversations have very strict latency requirements. To address this, Pavel Sountsov and Sushant came up with an innovative two-stage model that works as follows. First, a recurrent neural network looks at the conversation context one word at a time and encodes it in the hidden state of a long short term memory (LSTM). Below, we show an example with a context ‘Where are you?’. The context has three tokens, each of which is embedded into a continuous space and input to the LSTM. The LSTM state now encodes the context as a continuous vector. This vector is used to generate the response as a discretized semantic class.



Another interesting challenge we had to solve when generating predictions is controlling for message length. Sometimes none of the most probable responses are appropriate - if the model predicts too short a message, it might not be useful to the user, and if we predict something too long, it might not fit on the phone screen. We solved this by biasing the beam search to follow paths that lead to higher utility responses instead of favoring just the responses that are most probable. That way, we can efficiently generate appropriate length response predictions that are useful to our users.
Personalized for you
The best part about these suggestions is that over time they are personalized to you so that your individual style is reflected in your conversations. For example, if you often reply to “How are you?” with “Fine.” instead of “I am good.”, it will learn your preference and your future suggestions will take that into account. This was accomplished by incorporating a user's "style" as one of the features in a Neural Network that is used to predict the next word in a response, resulting in suggestions that are customized for your personality and individual preferences. The user's style is captured in a sequence of numbers that we call the user embedding. These embeddings can be generated as part of the regular model training, but this approach requires waiting for many days for training to be complete and it cannot handle more than a handful of millions of users. To solve this issue, Alon Shafrir implemented a L-BFGS based technique to generate user embeddings quickly and at scale. Now, you'll be able to enjoy personalized suggestions after only a short time of using Allo.
More than just English
The neural network model described above is language agnostic so building separate prediction models for each language works quite well. To make sure that responses for each language benefit from our semantic understanding of other languages, Sujith Ravi came up with a graph-based machine learning technique that can connect possible responses across languages. Dana Movshovitz-Attias and Peter Young applied this technique to build a graph that connects responses to incoming messages and to other responses that have similar word embeddings and syntactic relationships. It also connects responses with similar meaning across languages based on the machine translation models developed by our Translate team.
With this graph, we use semi-supervised learning, as described in this paper, to learn the semantic meaning of responses and determine which are the most useful clusters of possible responses. As a result, we can allow the LSTM to score many possible variants of each possible response meaning, allowing the personalization routines to select the best response for the user in the context of the conversation. This also helps enforce diversity as we can now pick the final set of responses from different semantic clusters.
Here’s an example of how the graph might look for a set of messages related to greetings:

I am also very excited about the Google assistant in Allo with which you can converse and get information about anything that Google Search knows about. It understands your sentences and helps you accomplish tasks directly from the conversation. For example, the Google assistant can help you discover a restaurant and reserve a table from within the Allo app when chatting with your friends. This has been made possible because of the cutting-edge research in natural language understanding that we have been doing at Google. More details to follow soon!
These smart features will be part of the Android and iOS apps for Allo that will be available later this summer. We can’t wait for you to try and enjoy it!
We wish to acknowledge the hard work of the following in building Smart Reply:
Pranav Khaitan, Sushant Prakash, Pavel Sountsov, Alon Shafrir, Max Gubin, Shu Zhang, Sunita Sarawagi, Ori Gershony, Sergey Nazarov, Hung Pham, Harini Krishnamurthy, Ryan Cassidy, Dave Citron, Patrick McGregor, Sujith Ravi, Dana Movshovitz-Attias, Peter Young, Vivek Ramavajjala
Quick links
Other posts of interest
-
May 23, 2025
Fine-tuning LLMs with user-level differential privacy- Algorithms & Theory ·
- Machine Intelligence ·
- Security, Privacy and Abuse Prevention
-

May 14, 2025
Deeper insights into retrieval augmented generation: The role of sufficient context- Data Mining & Modeling ·
- Generative AI ·
- Machine Intelligence
-
April 23, 2025
Introducing Mobility AI: Advancing urban transportation- Algorithms & Theory ·
- General Science ·
- Machine Intelligence