
Text-to-Speech for Low-Resource Languages (Episode 2): Building a Parametric Voice
December 15, 2015
Posted by Alexander Gutkin, Google Speech Team
This is the second episode in the series of posts reporting on the work we are doing to build text-to-speech (TTS) systems for low resource languages. In the previous episode, we described the crowdsourced data collection effort for Project Unison. In this episode, we describe our work to construct a parametric voice based on that data.
In our previous episode, we described building TTS systems for low resource languages, and how one of the objectives of data collection for such systems was to quickly build a database representing multiple speakers. There are two main justifications for this approach. First, professional voice talents are often not available for under-resourced languages, so we need to record ordinary people who get tired reading tedious text rather quickly. Hence, the amount of text a person can record is rather limited and we need multiple speakers for a reasonably sized database that can be used by others as well. Second, we wanted to be able to create a voice that sounds human but is not identifiable as a real person. Various concatenative approaches to speech synthesis, such as unit selection, are not very suitable for this problem. This is because the selection algorithm may join acoustic units from different speakers generating a very unnatural sounding result.
Adopting parametric speech synthesis techniques is an attractive approach to building multi-speaker corpora described above. This is because in parametric synthesis the training stage of the statistical component will take care of multiple-speakers by estimating an averaged out representation of various acoustic parameters representing each individual speaker. Depending on number of speakers in the corpus, their acoustic similarity and ratio of speaker genders, the resulting acoustic model can represent an average voice that is indistinguishable from human and yet cannot be traced back to any actual speakers recorded during the data collection.
We decided to use two different approaches to acoustic modeling in our experiments. The first approach uses Hidden Markov Models (HMMs). This well-established technique was pioneered by Prof. Keiichi Tokuda at Nagoya Institute of Technology, Japan and has been widely adopted in academia and industry. It is also supported by a dedicated open-source HMM synthesis toolkit. The resulting models are small enough to fit on mobile devices.
The second approach relies on Recurrent Neural Networks (RNNs) and vocoders that jointly mimic the human speech production system. Vocoders mimic the vocal apparatus to provide a parametric representation of speech audio that is amenable to statistical mapping. RNNs provide a statistical mapping from the text to the audio and have feedback loops in their topology, allowing them to model temporal dependencies between various phonemes in human speech. In 2015, Yannis Agiomyrgiannakis proposed Vocaine, a vocoder that outperforms the state-of-the-art technology in speed as well as quality. In 2013, Heiga Zen, Andrew Senior and Mike Schuster proposed a neural network-based model that mimics deep structure of human speech production for speech synthesis. The model has further been extended into a Long Short-Term Memory (LSTM) RNN. This allows long term memorization, which is good for speech applications. Earlier this year, Heiga Zen and Hasim Sak described the LSTM RNN architecture that has been specifically designed for fast speech synthesis. The LSTM RNNs are also used in our Automatic Speech Recognition (ASR) systems recently mentioned in our blog.
Using the Hidden Markov Model (HMM) and LSTM RNN synthesizers described above, we experimented with a multi-speaker Bangla corpus totaling 1526 utterances (waveforms and corresponding transcriptions) from five different speakers. We also built a third system that utilizes LSTM RNN acoustic model, but this time we made it small and fast enough to run on a mobile phone.
We synthesized the following Bangla sentence "এটি একটি বাংলা বাক্যের উদাহরণ" translated from “This is an example sentence in Bangla”. Though HMM synthesizer output can sound intelligible, it does exhibit some classic downsides with a voice that sounds buzzy and muffled. With the LSTM RNN configuration for mobile devices, the resulting audio sounds clearer and has improved intonation over the HMM version. We also tried a LSTM RNN configuration with more network nodes (and thus not suitable for low-end mobile devices) to generate this waveform - the quality is slightly better but is not a huge improvement over the more lightweight LSTM RNN version. We hypothesize that this is due to the fact that a neural network with many nodes has more parameters and thus requires more data to train.
These early results are encouraging for several reasons. First, they confirm that natural-sounding speech synthesis based on multiple speakers is practically possible. It is also significant that the total number of recordings used was relatively small, yet were able to build intelligible parametric speech synthesis. This means that it is possible to collect training data for such a speech synthesizer by engaging the help of volunteers who are not professional voice artists, for a short period of time per person. Using multiple volunteers is an advantage: it results in more diverse data, and the resulting synthetic voice does not represent any specific individual. This approach may well be the foundation for bringing speech technology to many more traditionally under-served languages.
NEXT UP: But can it say, “Google”? (Ep.3)
-
Labels:
- Speech Processing
Other posts of interest
-

April 17, 2024
Robust speech recognition in AR through infinite virtual rooms with acoustic modeling- Human-Computer Interaction and Visualization ·
- Machine Perception ·
- Speech Processing
-
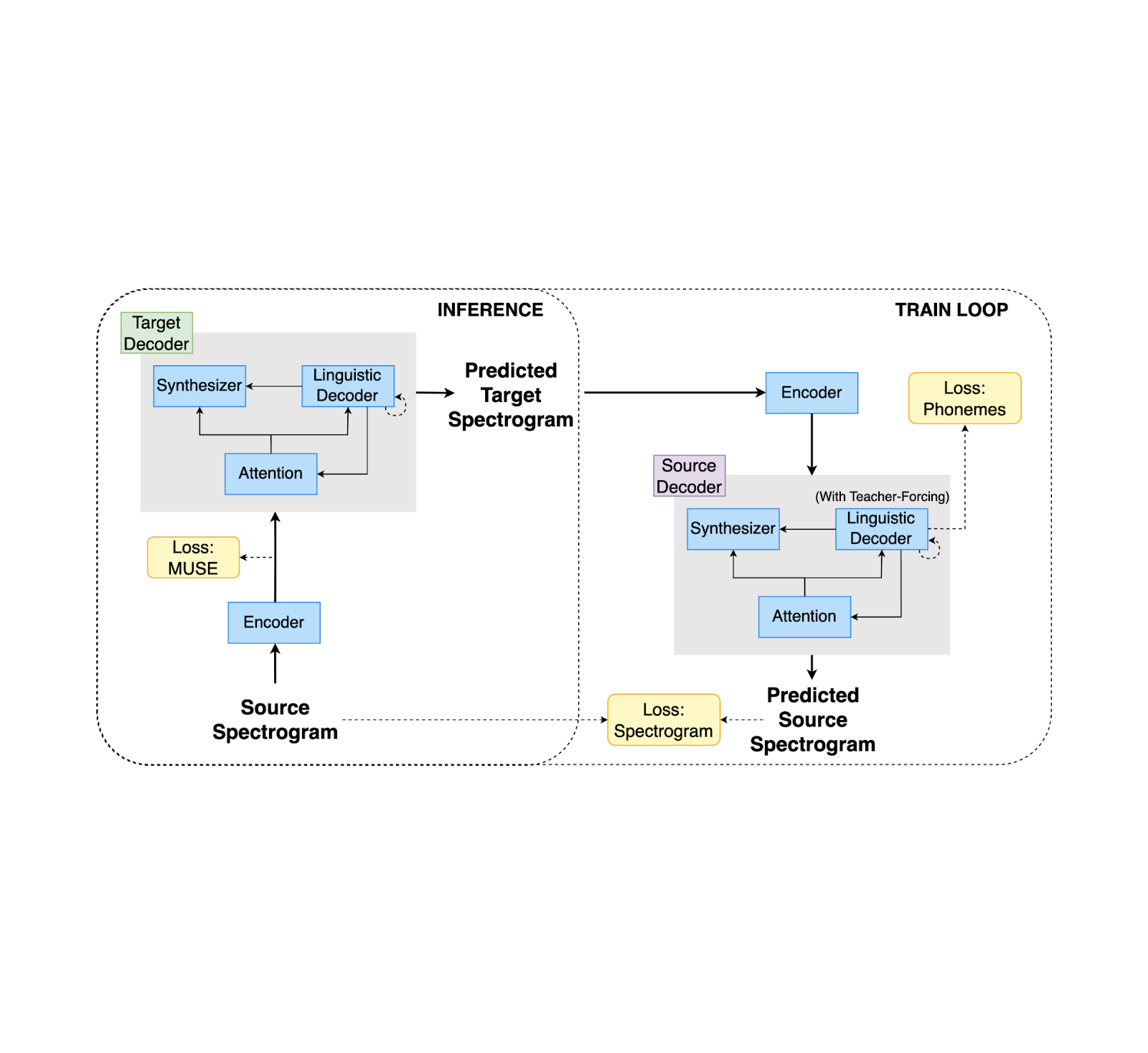
December 1, 2023
Unsupervised speech-to-speech translation from monolingual data- Machine Translation ·
- Product ·
- Speech Processing
-
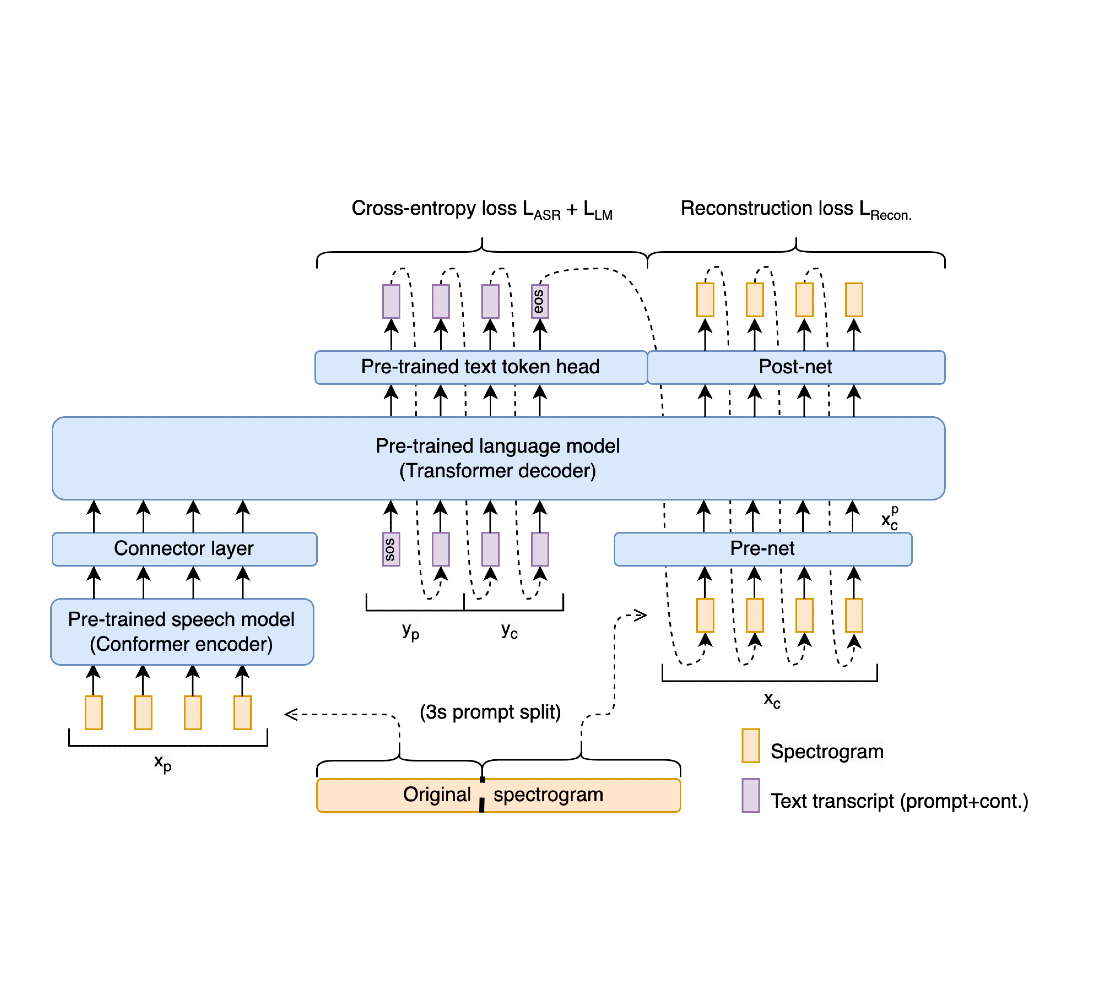
October 26, 2023
Spoken question answering and speech continuation using a spectrogram-powered LLM- Natural Language Processing ·
- Speech Processing