High Quality Object Detection at Scale
December 8, 2014
Update - 26/02/2015
We recently discovered a bug in the evaluation methodology of our object detector. Consequently, the large numbers we initially reported below are not realistic, due to the fact that our separately trained context extractor was contaminated with half of the validation set images. Therefore, our initial results were overly optimistic and were not attainable by the methodology described in the paper. Re-evaluating our initial results, we have restricted ourselves to reporting only the single-model results on the other half of the dedicated validation set without retraining the models. With the updated evaluation, we are still able to report the best single-model result on the ILSVRC 2014 detection challenge data set, with 0.43 mAP when combining both Selective Search and MultiBox proposals with our post-classification model. The original draft of our paper "Scalable, High Quality Object Detection" has been updated to reflect this information. We are deeply sorry if our initial reported results caused any confusion in the community. Original post follows below.
-C. Szegedy, S. Reed, D. Erhan, and D. Anguelov
The ILSVRC detection challenge is an influential academic benchmark for measuring the quality of object detection. This summer, the GoogLeNet team reported top results in the 2014 edition of the challenge, with ~2X improvement over the previous year’s best results. However, the quality of our results came at a high computational cost: processing each image took about two minutes on a state-of-the-art workstation.
Naturally, we began to think of how we could both improve the accuracy and reduce the computation time needed. Given the already high quality of previous results like those of GoogLeNet[6], we expected that further improvements to detection quality would be increasingly hard to achieve. In our recent paper Scalable, High Quality Object Detection[7], we detail advances that instead have resulted in an accelerated rate of progress in object detection:
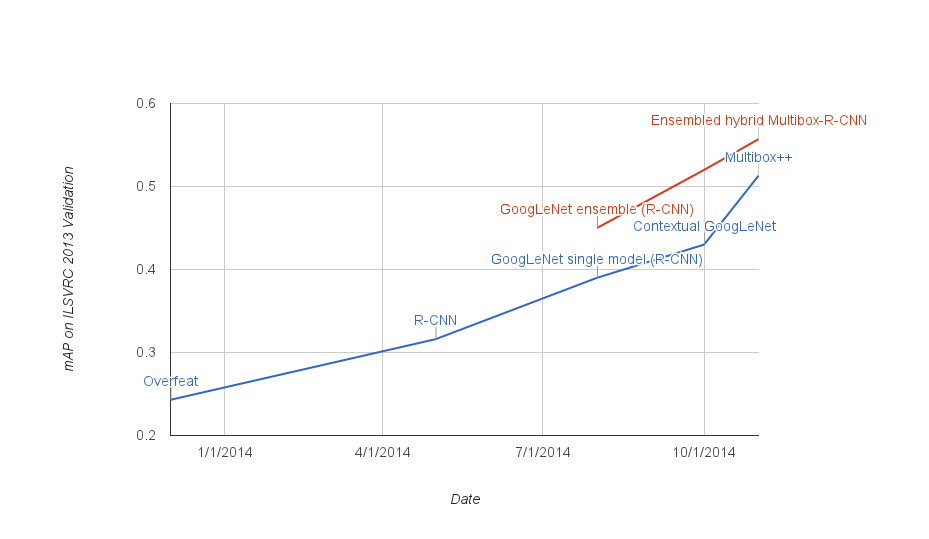
 |
| Evolution of detection quality over time. On the y axis is the mean average precision of the best published results at any given time. The blue line shows result using individual models, the red line is multi-model ensembles. Overfeat[8] was the state-of-the-art at end of last year, followed by R-CNN[1] published in May. The later measurement points are the results of our team.[6,7] |
Most current approaches for object detection employ two phases[1]: in the first phase, some hand-engineered algorithm proposes regions of interest in the image. In the second phase, each proposed region is run through a deep neural network, identifying which proposed patches correspond to an object (and what that object is).
For the first phase, the common wisdom[1,2,3,4] was that it took skillfully crafted code to produce high quality region proposals. This has come with a drawback though: these methods don’t produce reliable scoring for the proposed regions. This forces the second phase to evaluate most of the proposed patches in order to achieve good results.
So we revisited our prior “MultiBox” work[5], in which we let the computer learn to pick the proposals to see whether we could avoid relying on any of the hand-crafted methods above. Although the MultiBox method, using previous generation vision network architectures, could not compete with hand-engineered proposal approaches, there were several advantages of fully relying on machine learning only. First, the quality of proposals increases with each new improved network architecture or training methodology without additional programming effort. Second, the regions come with confidence scores which are used for trading off running time versus quality. Additionally, the implementation is simplified.
Once we used new variants of the network architecture introduced in [6], MultiBox also started to perform much better; Now, we could match the coverage of alternative methods with half as many proposal patches. Also, we changed our networks to take the context of objects into account, fueling additional quality gains for the second phase. Furthermore, we came up with a new way to train deep networks to learn more robustly even when some objects are not annotated in the training set, which improved both phases.
Besides the significant gains in mean average precision, we can now cut the number of evaluated patches dramatically at a modest loss of quality: the task that used to take 2 minutes of processing time for a single image on a workstation by the GoogLeNet ensemble (of 6 networks), is now performed under a second using a single network without using GPUs. If we constrain ourselves to a single category like “dog”, we can now process 50 images/second on the same machine by a more streamlined approach[7] that skips the proposal generation step altogether.
As a core area of research in computer vision, object detection is used for providing strong signals for photo and video search, while high quality detection could prove useful for self-driving cars and automatically generated image captions. We look forward to the continuing research in this field.
References:
[1] Rich feature hierarchies for accurate object detection and semantic segmentation
by Ross Girshick and Jeff Donahue and Trevor Darrell and Jitendra Malik (CVPR, 2014)
[2] Prime Object Proposals with Randomized Prim’s Algorithm
by Santiago Manen, Matthieu Guillaumin and Luc Van Gool
[3] Edge boxes: Locating object proposals from edges
by Lawrence C Zitnick, and Piotr Dollàr (ECCV 2014)
[4] BING: Binarized normed gradients for objectness estimation at 300fps
by Ming-Ming Cheng, Ziming Zhang, Wen-Yan Lin and Philip Torr (CVPR 2014)
[5] Scalable Object Detection using Deep Neural Networks
by Dumitru Erhan, Christian Szegedy, Alexander Toshev, and Dragomir Anguelov
[6] Going deeper with convolutions
by Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke and Andrew Rabinovich
[7] Scalable, high quality object detection
by Christian Szegedy, Scott Reed, Dumitru Erhan and Dragomir Anguelov
[8] OverFeat: Integrated Recognition, Localization and Detection using Convolutional Network by Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus and Yann LeCun
* A PhD student at University of Michigan -- Ann Arbor and Software Engineering Intern at Google↩